From the beginning, when we first learned about a developing network of people focused on exploring how we might preserve software, our team in Charlottesville saw a significant convergence of interests on the topic between the UVA Library and APTrust (APTrust.org, a sixteen institution consortium working together on digital preservation headquartered at the Library). Certainly, the primary anchor point for our involvement with both the EaaSI and FCoP projects has been the UVA Library itself. That said, we believe that APTrust’s involvement as a contributing partner to the Library’s work helps APTrust staff and its members understand how emulation may address some of our perplexing challenges in digital preservation at scale, including how pursue a better strategy than a never-ending cycle of format migrations.
The technologies used (Ansible, Docker) by EaaSi were coherent with the tools we were already using on the APTrust as well as on UVa Library IT side which made the start into the project quick and somewhat seamless. While there is still room for improvement, getting started with emulation use-cases was quickly possible.
Many of our services are run on AWS already therefore it was a natural choice for us to run EaaSi on AWS as well. Since our deployments and provisioning are standardized we are able to scale the node as needed, though we haven’t had the need yet for the testing phase.
UVA shares the distinction with new node member Georgia Tech as lucky participants in both the FCoP and EaaSI projects and cohorts, and this has helped us better understand and build out our ideas and experience for use cases, including the technical build that Christian described above. Being dual participants also provides us with a way to both show and talk to university constituencies who might be interested in software preservation and emulation through the EaaSI project.
Our work in FCoP and EaaSI started out small, but sometimes use cases can be a cascade once people have an understanding and shared language around the work and their place within it. One example is on the archives side, where we had a specific use case for our FCoP project where we knew we had commercial software in the collection and software dependent CAD/BIM digital materials that belonged to a particular donor.
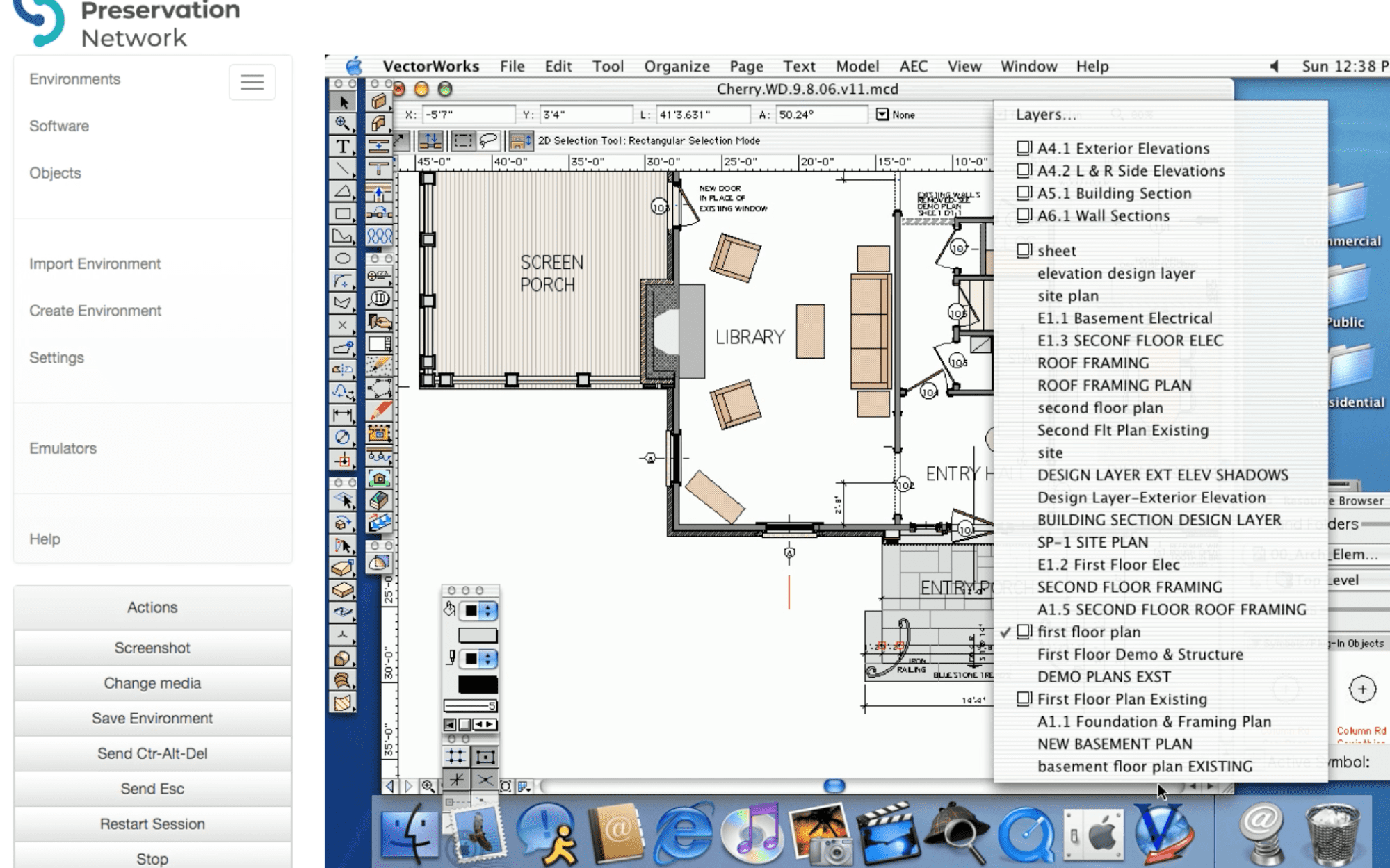
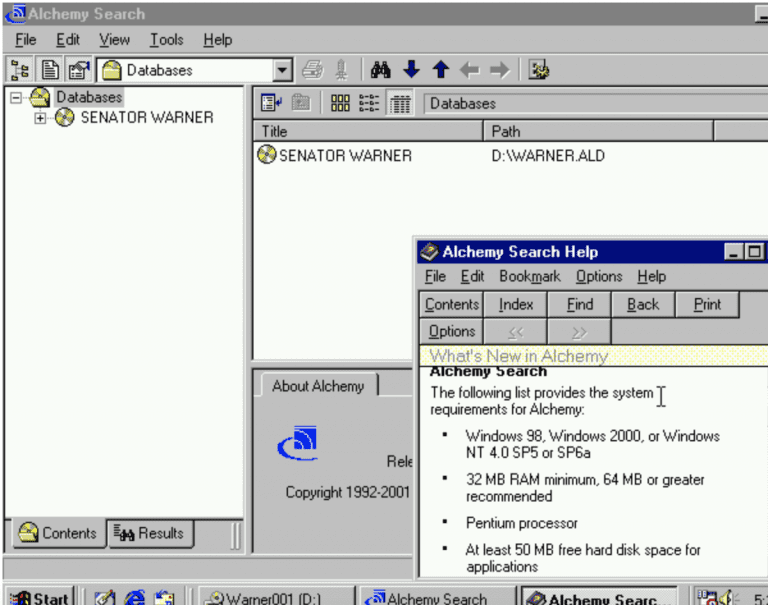
However, during the course of our initial focus on software for an architectural collection, other archival collections with software and software-dependent materials also revealed themselves as potential archival use cases: constituent mail in an antiquated database reliant on Windows 98 in a congressional collection, CD-ROMs that are part of faculty papers, and more. Sometimes these use cases were sparked by conversations, other times they were lesser known components of collections that came to light after processing or a research request. We imagine (and hope!) this kind of cascade won’t be uncommon for other EaaSI nodes, particularly as we work to build networks and community within our own institutions as well build on each others’ work in computing architectures, software, and environments.
We’ve also found that while UVA previously focused on leading our FCoP work over the last year on archival architectural collections, participating as a dual team member in the EaaSI has allowed us also think and act more broadly about building coalitions at UVA who are interested in software preservation and emulation for a wide range of collections.
Cultural heritage data, research data, and legacy digital humanities project use cases are also a part of our focus with EaaSI at UVa, and work as part of the EaaSI team has already provided an economy of scale when building out and testing use cases related to these areas of interest. A recent example relates to UVA’s participation in the February 2020 IDCC FCoP and EaaSI workshop, Preparation and Process: Software Preservation and Emulation for Research Data, where each member of the workshop team was tasked with developing an environment around an existing use case for use by the workshop audience.
Several of us had overlaps in types of use cases (similar humanities focus with time periods where cases were reliant on technologies like Flash and/or VRML, for example), and therefore the approach for thinking through and trying environment builds was easier, as well as the ability to discuss and test approaches with the shared cohort. It’s exciting to see this in practice, and to think about where this work may go as we keep building on other EaaSI project goals like shared metadata and the implementation of standard identify management systems.

Beyond creating shared environments for the workshop, it was also an opportunity to think about the role of EaaSI in the software curation lifecycle around research and cultural data and our place within it. The first version of (literally) mapping out what this looks like within a research context was created for the IDCC workshop, and demonstrates how we currently envision EaaSI in our own library workflows; as an important component in the life cycle of the preservation and maintenance of software and digital materials.
For those of us with direct involvement both at the UVA Library and in APTrust, using the FCoP project to provide a pilot use-case, and then building on these cases to help implement an EaaSI node has helped us see roles for services such as APTrust in giving groups of institutions access to the pieces needed for dynamic construction of emulation environments to make specific content usable. We regard both projects as valuable capability-building activities that together help create a core group of people with the skills to help design, operate and provide access to these still-evolving services. Both projects have taught us about the effort and infrastructure we need for the services. Together with SPN, we’ve all also begun to consider the complex challenges of financial-modeling and governance-planning that will have to be in place if we’re going to offer collaborative services that will make a real difference on a national/international scale. We’re looking forward to continuing to build out our collaborations and use cases for what comes next!